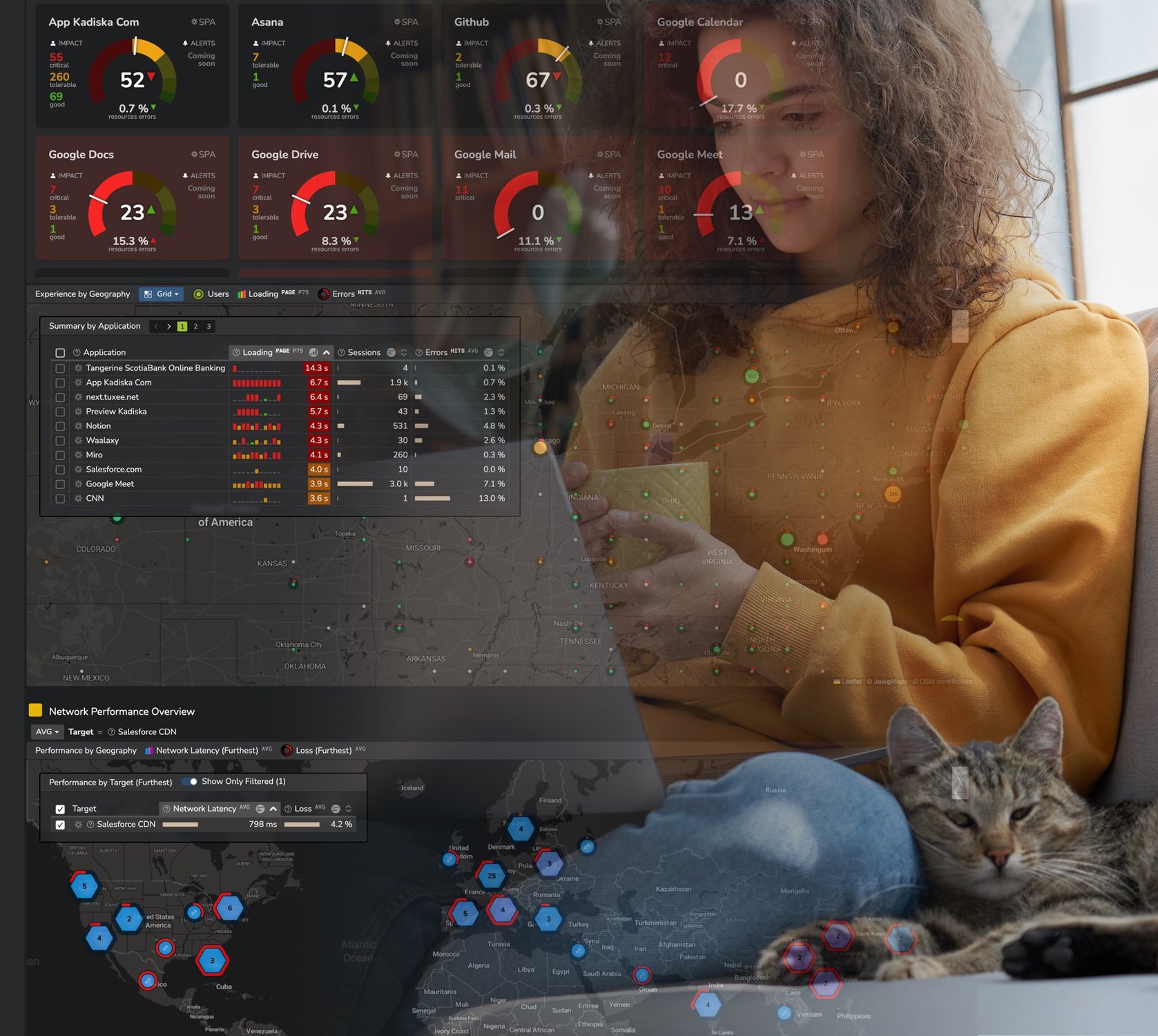
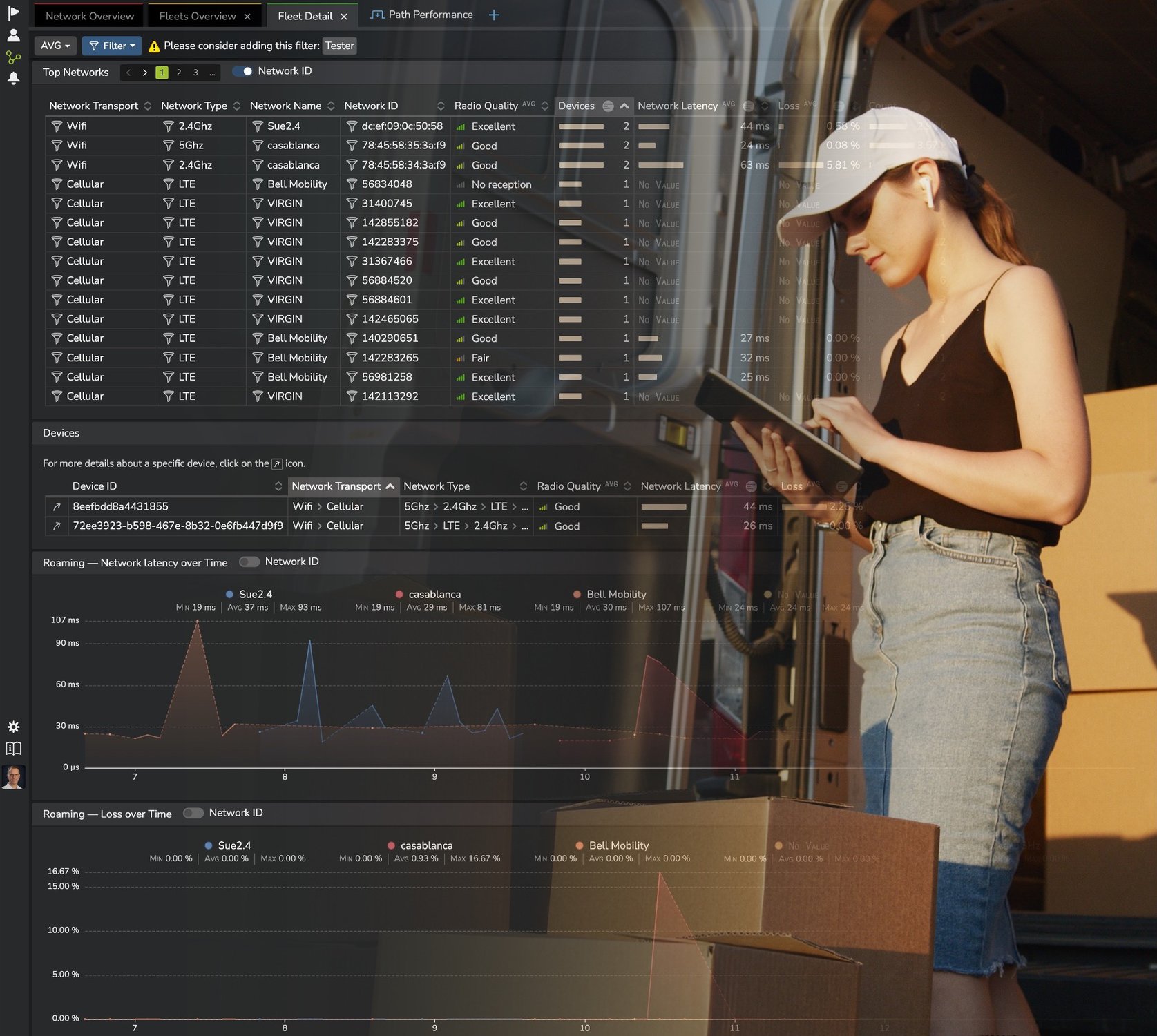
Toute personne fournissant des applications sur les réseaux considère le temps de réponse du réseau comme un facteur critique pour l’expérience numérique.
Expliquons les bases de la latence du réseau :
- Qu’est-ce que la latence du réseau ?
- Comment mesurer la latence réseau ?
- How it works? Comment cela fonctionne-t-il ? Ce qui génère une réponse lente ou rapide du réseau.
- Comment la réduire ?
Qu’est-ce que la latence du réseau ? Une définition
Tout d’abord, la latence est le délai nécessaire à un paquet pour voyager sur un réseau d’un point à un autre. Dans la plupart des cas, nous ferons référence à la latence du réseau comme étant le temps nécessaire pour qu’un paquet passe d’un client/utilisateur à un serveur à travers le réseau.
Plusieurs types de latence réseau
Deuxièmement, il existe de multiples façons de mesurer la latence du réseau :
- délai ou latence unidirectionnelle : il s’agit du temps nécessaire à un paquet pour aller d’une extrémité (le dispositif de l’utilisateur) à une autre extrémité (le serveur).
- le délai aller-retour : il s’agit du temps nécessaire pour qu’un paquet aille d’un bout à l’autre, et inversement.

Selon la façon avec laquelle vous essayez de mesurer la latence, vous obtiendrez soit un délai aller-retour, soit un délai unidirectionnel. Comme les conditions sur le réseau varient et peuvent être différentes dans les deux sens, les deux types de mesures ont des avantages et des inconvénients.
Comment mesurer la latence du réseau ?
Examinons les différentes façons de mesurer la latence.
-
Capture du trafic pour le trafic basé sur TCP
La capture des paquets donnera une idée du délai aller-retour à condition de capturer le trafic basé sur le protocole TCP. Le protocole TCP/IP comprend un mécanisme d’accusé de réception, qui peut constituer une bonne base pour évaluer la latence dans les deux sens entre un client et un serveur.
Cette approche présente deux inconvénients majeurs :
- Premièrement, les accusés de réception peuvent être retardés et traités de différentes manières selon le système (lisez cet article pour plus d’informations).
- Deuxièmement, l’état des systèmes (clients et serveurs) peut avoir un impact sur le niveau de priorité accordé au traitement du mécanisme d’accusé de réception ; par exemple, un serveur surchargé peut retarder les ACK et générer des valeurs RTT élevées, qui ne correspondent pas à la latence réelle.
Les mesures auxquelles vous pouvez vous attendre :
- RTT RTT (Round Trip Time, temps d’aller-retour)
- CT CT (Connection Time, durée de connexion) qui mesure le temps nécessaire pour exécuter l’établissement de la session TCP (SYN – SYN/ACK – ACK). Cette mesure a un avantage : les systèmes traitent ces étapes avec une priorité plus élevée, ce qui signifie qu’elles subissent rarement un retard et ne génèrent pas de mesures de latence erronées. D’un autre côté, elle a aussi un inconvénient : elle représente un aller-retour et demi, ce qui n’est pas facile à interpréter.
- TTFB Dans le passé, le TTFB (Time To First Byte, tittéralement le “temps de chargement du premier octet”) était parfois considéré comme une évaluation de la latence, mais ce n’est plus le cas. Auparavant, certains d’entre nous le considéraient comme l’intervalle de temps entre le paquet SYN et le premier paquet de réponse du serveur. Aujourd’hui, le TTFB correspond à la mesure du temps de réponse entre une requête web et le premier paquet renvoyé en réponse par le serveur. Même dans sa définition ancienne, il reflète mal la latence réseau puisqu’il intègre le temps de réponse du serveur.
Une remarque sur la mesure de la latence réseau basée sur la capture du trafic : sur UDP, on peut facilement surveiller la gigue (en termes simples, la variation standard de la latence) mais on ne peut pas mesurer la latence de cette façon.
En quelques mots, vous pouvez mesurer la latence avec une approche basée sur le trafic en capturant le trafic réseau. L’avantage est que vous n’avez pas besoin de contrôler l’une des deux extrémités. Le principal inconvénient est que cette métrique est particulièrement imprécise.
-
Test actif du réseau
Vous pouvez également tester la latence de votre réseau en émettant des paquets et en vérifiant le temps nécessaire pour qu’ils fassent le trajet dans un sens ou dans l’autre.
Test basé sur le protocole ICMP
- L’ordinateur client envoie un paquet de demande d’écho ICMP (communément appelé « ping ») à l’ordinateur cible.
- La machine cible reçoit le paquet de demande et construit un paquet de réponse d’écho ICMP.
L’ordinateur client utilisera les horodatages correspondant à l’émission de la demande d’Echo et à la réception de la réponse Echo pour calculer le temps d’aller-retour.
Les inconvénients de l’ICMP sont :
- ICMP est traité sur les réseaux d’une manière différente des protocoles qui transportent des données d’application (principalement TCP et UDP). Par exemple, il peut avoir une priorité plus ou moins élevée sur les réseaux des opérateurs.
- Le traitement des requêtes ICMP par les périphériques réseau est un service de seconde classe, ce qui peut avoir un impact sur la qualité de la mesure de la latence.
- Le traitement ICMP peut être désactivé sur le périphérique cible qui peut tout simplement ne pas répondre aux requêtes ICMP.
Tests basés sur UDP / TCP
Vous pouvez envoyer des paquets TCP ou UDP et valider la réception des paquets.
L’avantage est qu’il est possible de mesurer la latence dans un sens et d’obtenir des résultats plus précis.
La contrainte est que vous devez soit avoir le contrôle des deux extrémités, soit utiliser un protocole de test qui doit être supporté par les deux extrémités, par exemple TWAMP.
Comment ça marche : qu’est-ce qui détermine la latence du réseau ?
Les 4 principaux facteurs qui déterminent la latence sont les suivants :
-
Propagation
Il s’agit du temps nécessaire à un paquet pour passer d’une interface d’un périphérique réseau à l’interface d’un autre périphérique réseau via un câble. Ce facteur est régi par les règles de la physique, vous pouvez donc vous attendre à ce qu’il soit très stable (environ la vitesse de la lumière x 2/3). En quelques mots, plus la distance à parcourir dans votre réseau est courte, plus la latence sera faible.
2 & 3. Traitement et sérialisation
Le temps de sérialisation sur un équipement réseau est le temps nécessaire pour qu’un paquet soit sérialisé pour être transmis sur un câble. Il dépend de la taille du paquet mais reste constant et relativement négligeable.
Le temps de traitement est beaucoup plus variable sur chaque routeur ou équipement sur le chemin réseau. Il dépend de :
- les services fournis par chaque routeur (mode bridge, routage, filtrage, cryptage, compression, tunneling)
- La capacité de l’appareil par rapport à sa charge actuelle.
Si l’on considère le chemin global, le nombre de sauts/routeurs par lesquels passe le trafic aura un impact sur le temps global nécessaire à la sérialisation et au traitement inclus dans la latence totale du réseau.
4. Mise en file d’attente
Il s’agit du temps passé en moyenne par chaque paquet dans la file d’attente du routeur.
Cela dépend surtout de la taille de la file d’attente.
La taille de la file d’attente dépend de la taille globale du trafic (par rapport à sa capacité) et de sa rapidité.
Des files d’attente plus longues se traduiront par plus de latence et de gigue.
Comment cela se traduit-il en termes de latence pour un chemin réseau global ?
Prenez en considération ces facteurs dans le contexte d’un chemin réseau de bout en bout.

Les facteurs clés pour le chemin réseau de bout en bout seront par ordre décroissant d’importance :
Moteurs et principaux facteurs les influençant
- Propagation
La distance géographique sur le chemin global du réseau détermine ce temps.
- Traitement
Le temps de traitement global dépend de :
- Nombre de sauts sur le chemin
- Type de fonction activée
- Charge par rapport à la capacité pour chaque routeur
- Mise en file d’attente
Le temps d’attente global dépend de :
- la taille de la file d’attente (donc la charge par rapport à la capacité du routeur ou de la liaison)
- Nombre de sauts sur le chemin avec mise en file d’attente
- Sérialisation
Le temps de sérialisation global dépend de :
- Nombre de sauts sur le chemin
- Taille des paquets
Prochaines étapes
- Premièrement, comprenez l’impact de la latence sur l’expérience numérique de vos clients et utilisateurs.
- Découvrez comment vous pouvez mesurer les temps de réponse du réseau
- Troisièmement, décelez ce que vous pouvez faire en cas de latence élevée ? Comment la réduire ?